project three - fateful findings
When we hear about an airplane accident, there are a few things we always want to know. Where did it happen? Is everyone okay? And, of course: why did it crash?

This recent New York Times headline neatly sums up three of the most common reasons. Of course, it’s almost never just one thing. A bad situation caused by weather or mechanical failure can be made worse by pilot error, or a small mistake can cause damage that leads to a more severe accident. But overall, aviation accidents involve either some degree of human error, or not. I wanted to see if I could build a model that could figure out which.
getting the data
The National Transportation Safety Board (NTSB) is the federal agency that investigates all aviation accidents1 in the United States. They’re so good at it that foreign governments often contract the NTSB to fly in and investigate their own accidents.
And because they’re a government agency, they publish all of their investigation reports online, for free, where I can grab them and do all the data science I want.
While it’s possible to look up and browse through individual reports on their website, making use of the full database of accident reports requires a little more work. The real good stuff is kept not on a nice user-friendly site, but in a bare-bones directory. Inside the Access folder is a single file, avall.zip, which contains a massive Microsoft Access database comprising the investigation data for every aviation incident since 1982. (I didn’t even touch the pre-1982 stuff, which is also available but surrounded by sea monsters and dragons).
So now I had this 1.3 gigabyte Access .mdb file, which was great, except that (a) I wanted to use PostgreSQL, a completely different relational database system, and (b) I have a Mac, and for ~some reason~ Microsoft doesn’t like to port their flagship business software to a rival platform. There are apps that will read and/or convert Access databases to other formats, like this one ($19!), but I’m a big cheapskate and wanted to do this myself.
Open source to the rescue! A gentleman named Brian Bruns developed a suite called mdbtools which can do various things with .mdb files, including, crucially, exporting them to .csv. With mdbtools, all it took to get the file into PostgreSQL was a couple of one-liners, iterated for each table. First, on the command line:
mdb-schema avall.mdb postgres | tr 'A-Z' 'a-z' | psql -d avall
mdb-export avall.mdb $tablename > ./$tablename.csv
and (in the psql client, into the new avall database):
\copy $tablename from './$tablename.csv' with delimiter ',' csv header;
where $tablename is the name of each table in the database.
81,701 bad days
Now it was time to figure out what exactly I had. The NTSB database (which they call the eADMS) is a complex hierarchy of twenty related tables, encoding everything from the degree of severity of each person’s injury to the manufacturer and horsepower of every jet engine. This chart shows an earlier version of this hierarchy. events is at the top, with aircraft just below it, since an event can involve two or (very rarely) three separate aircraft.2 This newer chart more accurately depicts the most recent database layout, including the all-important new Findings table, but is also a lot harder to read.
There’s an ‘old’ and a ‘new’ version, because in 2008, the NTSB overhauled their system of encoding the reasons why a plane crashes. Pre-2008, it was a three-part system divided into Occurrences, Phases of Operation, and Causes/Factors, each with dozens or hundreds of numerical codes that were hand-entered into a vintage DEC-10 mainframe by people I like to imagine living eight floors underground and subsisting on nothing but instant coffee. If you’re interested, the old coding manual is available online and it smells like an ashtray.
This system was complicated, and made it hard to figure out exactly what happened in any given accident. The codes for Causes/Factors were a mixture of aircraft parts, weather conditions, light conditions, maintenance problems, and a whole mess of “modifiers,” including “person modifiers” (i.e., mistakes). Since any accident could involve multiple aircraft, each with multiple “occurrences,” and each of those with a mixture of causes, there’s no way to programmatically determine a rough root cause for any particular crash.
Luckily for me, the 2008 overhaul radically simplified this system. The “occurrences” system was scrapped, and all of the possible causes were organized into four broad categories:
- Aircraft: basically, something physically breaking or malfunctioning
- Personnel issues: a mistake made by the person flying the plane (or occasionally a copilot or flight engineer)
- Environmental issues: usually weather or light conditions, but also including unfortunately contact with wildlife
- Organizational issues: the rarest category, reserved for problems caused by ground crews, airline operators, and the like
With a fifth category, “not determined,” if the cause of the accident was unknown.
Since I wanted to label accidents as being either caused by human error or not, this new system made my life a lot easier. The tradeoff is that it shrank the size of my dataset: while there were a grand total of 81,701 incidents in the complete data, only about 14,000 of those used the post-2008 coding system. That was a tradeoff I was willing to make, if it meant I could use a consistent and accessible method of encoding my key label variable.
In order to understand exactly how this Findings field was used, I had to look at the actual accident reports. Here’s one that definitely falls under the “human error” rubric:

No fewer than six separate causes and factors are “personnel issues” of various kinds, and three of those are tagged as “causes” (rather than less important “factors”), making this a pretty unambiguous case of pilot error.
And here’s another famous one that was definitely not pilot error:

Here the primary cause was a flock of dreadful geese. One “organizational issue” comes into play, but Sully’s Hudson River Adventure probably shouldn’t be classified as a pilot-caused crash.
It’s worth pointing out here that both of these are fairly unrepresentative of the data at large. The big commercial-plane crashes that make the headlines are extremely rare. Nearly all of the accidents in the data - more than 95%! - involve very small planes, often flown by hobbyists, not professional pilots.
Unfortunately, after looking at more accidents, the “cause” and “factor” tags were not as helpful as I had hoped. Many accidents were missing these tags altogether, and I found case after case where pilot error was listed as a “factor” but was ultimately decisive.
In the end, I decided to count an accident as “human error” if any of the listing findings were a “personnel issue.” Now I had my dependent variable! And now it was time to dig through more than a dozen tables and decide what independent variables I could use to explain it.
data extraction
The eADMS database contains hundreds of columns, any number of which could be a potentially useful component of my model. To choose the ones I wanted to work with, I did several passes through each table. First, I simply wrote down the name and description of each column that I figured was even a remotely plausible part of a predictive model, even if I didn’t really plan on ever using it. This just helped me get my bearings in terms of what was even available.
This first pass gave me about 75 variables, mostly in the events and aircraft tables, but also including engines, Flight_Crew, injury, and flight_time. These included everything from the temperature and dew point at the time of the accident to whether each crew member was wearing a seatbelt. Time to refine a little further.
A second pass (throwing out stuff that was too similar to another variable, or seemed useless, or had too many non-missing values) gave me a working list of 47 columns that I figured were worth at least pulling out of the PostgreSQL database and into Python/pandas for further investigation.
Easier said than done. The complex structure of the database, with three separate levels of identifying keys (event, aircraft, and crew member) meant that extracting data required a set of seven complex SQL queries. Here’s just one, which extracts interesting columns for the second crew member on a craft:
CREATE OR REPLACE VIEW crew_2 AS
(
WITH xp AS
(
SELECT
ev_id,
aircraft_key,
crew_no,
flight_hours
FROM
flight_time
WHERE
flight_type = 'TOTL'
AND flight_craft = 'ALL '
)
SELECT
fc.ev_id,
fc.aircraft_key,
fc.crew_no,
fc.crew_category,
fc.crew_age,
fc.med_certf,
fc.med_crtf_vldty,
fc.seatbelts_used,
fc.shldr_harn_used,
fc.crew_tox_perf,
fc.pc_profession,
xp.flight_hours
FROM
flight_crew AS fc
LEFT JOIN xp ON
fc.ev_id=xp.ev_id
AND fc.aircraft_key=xp.aircraft_key
AND fc.crew_no=xp.crew_no
WHERE
fc.crew_no = 2
);
SQL is fun and easy! It uses English words and you can whitespace it any way you want!
My final query tied everything up into a single dataframe, with each row representing a single aircraft, my primary unit of analysis. That meant that a single accident could occasionally be represented by two rows, and also that I had two separate sets of crew-member columns, for the first and (if present) second crew member: not perfectly tidy, but no big deal, as I ended up not using the second-crew-member columns anyway.
data to features
Now I had my raw data. But there were some things that needed to be sorted out before I could start modeling. Many of my columns were categorical, and needed to be converted to numeric values. My continuous columns had some odd outliers I needed to examine. And nearly everything had some amount of missing data.
For categorical data with only two classes (for example, if there was a second pilot, or if the aircraft operator had a commercial certificate), transformation was only a matter of coding one class as 0 and the other as 1. But for multi-class columns (like the type of flight, or type of aircraft), I had some choices to make. I could use one-hot encoding, transforming each category (minus one) to a 0/1 dummy variable; or, I could choose one or two of the most interesting classes to be coded as 1, and all others as 0. Since many of these categorical columns had dozens of possible categories, I generally chose the latter method: for example, I counted instructional flights as 1 and all others (cargo, ferry, skydiving, etc.) as 0.
There was some interesting stuff in my categorical variables: for example, I discovered that there were 22 accidents that involved blimps, and exactly one rocket ship.
There was one column of data - medical certificate level - that was obviously ordinal (that is, with a ranked hierarchy of categories). I transformed this to a single column with numbers from 0 (no certificate) to 5 (Class 1 certificate). This isn’t ideal, since I’m essentially saying that a Class 2 certificate (scored as 4) is “twice as good” as a Sport Pilot certificate (scored as 2) for the purpose of my model. Something to keep in mind.
For each columns of continuous data (i.e., representing actual counts or values of something, like airframe weight or distance from airport), I checked each column for strange values and outliers that might be mis-entered data or something else that I don’t want.
I found several issues I needed to fix. For example, the column with the total flight hours of the airframe had numerous values like 999, 9999, 99999, all of which I interpreted as missing data and changed to NaN. There were a handful of aircraft listed with over 1,000 seats, which (on individual inspection) were definitely some kind of data error.
Not all strange values were actually wrong. I found a single craft in the dataset with a listed airframe weight of 4 pounds, which I thought must be a mistake. But when I looked up the NTSB report, it turned out to be a remote control drone that had collided with a helicopter near Staten Island.
The final issue I had to deal with was missing data. This was a serious issue - nearly all of my columns had at least a few null values, and some of them had many. Simply dropping every row that had a null value in any of my feature columns wasn’t feasible, because it would have reduced the size of my dataset to almost nothing. In the end, I decided not to use some of the features with the largest number of null values (such as my second-crew-member data), and for the rest, impute either the majority class (for categorical data) or the median (continuous data). Again, this isn’t ideal! Given more time and resources, it would have been better to use the known data to make some reasonable assumptions about the imputed data - for example, using the model of aircraft (if known) to estimate the gross airframe weight.
modeling
The graphs below look nice (thanks Tableau!), but they are a dire warning about how hard it was going to be to predict the cause of accidents from this data.
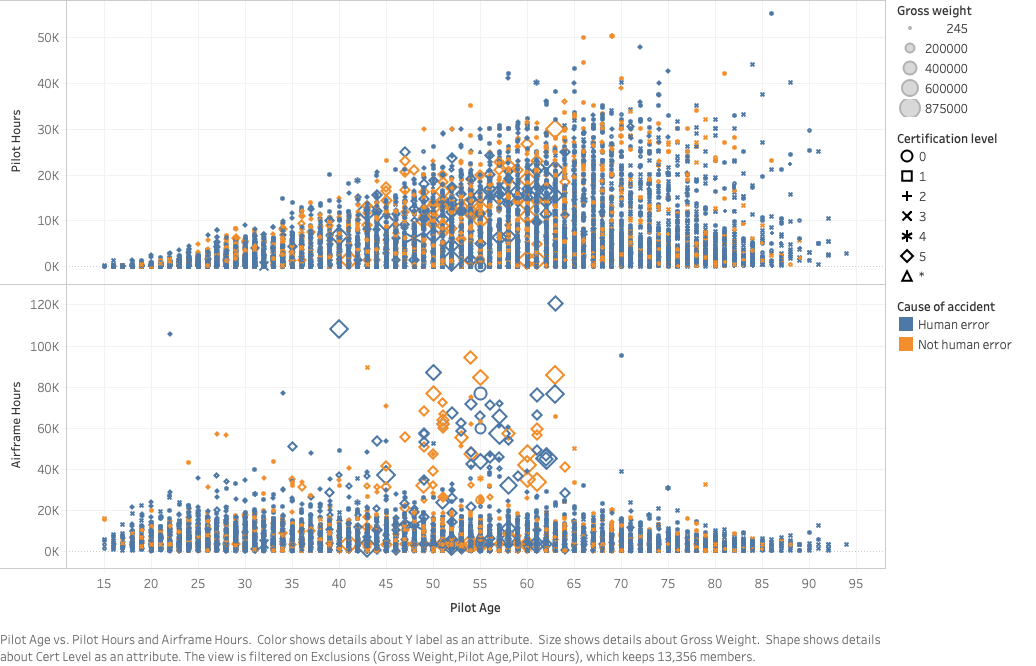
Several of my features are shown here: the age and experience (pilot hours) of the pilot, the age of the aircraft (airframe hours), the gross weight of the craft (indicated by the size of the dot), and the pilot’s medical certificate level. Finally, each dot is colored by my target class: blue for a human-caused accident, and orange for not.
The problem is that the orange and blue dots are completely mixed together - nothing in this data appears to help separate them at all. This graph only shows a handful of features, but I can tell this is going to be an issue.
Before I started modeling, I wanted to establish some baselines targets for various metrics (like accuracy and F1 score). To do this, I wrote three “dumb models”:
- One simply guessed at random (50/50) whether a given accident was caused by human error or not.
- One was the same as above, but guessed randomly with an 80/20 ratio, similar to the actual distribution of classes.
- One just always predicted that the accident was human-caused.
If my model couldn’t do better than these, then I was in trouble.
I also didn’t yet know exactly which of my dozens of potential features I wanted to include in my model, or even what kind of model to use. But I had to start somewhere, so I picked several of the most likely-seeming ones, split out my training and testing sets, then tried out a variety of classification models: k-nearest neighbors, Gaussian naive Bayes, random forest, SVM, and logistic regression.
None of these worked spectacularly well. In particular, most of the models under-predicted the number of accidents not caused by human error - for example, the SVM model predicted that only 14 of the test-set cases were not-human error (the actual number was 704).
The problem - well, one of the problems - was that my data was fairly unbalanced, with about four times as many human-error accidents as not. This made it harder for my models to learn what features were present in these not-human-error accidents. To combat this, I used an oversampling strategy (SMOTE) to artificially generate data points in my minority class.
Running the same series of models on the SMOTE’d data produced significantly better results. Some of the best metrics came from the logistic regression model. Since this model has some other advantages (speed, interpretability, power to assign probabilities), I decided to focus on logistic regressions for the rest of my modeling.
tuning
Now I had chosen a model pipeline (SMOTE plus logistic regression). The next step was to tune my hyperparameters. I focused on two:
- SMOTE sampling strategy - how many simulated minority-class to generate, as a percentage of the majority class
- Threshold: should the class-dividing threshold be the default of 0.5, or should there be a higher threshold for sorting a test row into the positive category?
Because logistic regression is so fast, I could try lots of hyperparameters at once, and graph their performance in terms of my favorite metrics (accuracy and F1 score). This made tuning these pretty simple.
More importantly, I had to tune the parameters themselves. What features should be included? Should they be transformed in any way?
This involved a lot of trial and error. Do I classify instructional flights based on the type_fly column, or crew_category? Is time since last inspection important? What about visibility?
In the end, I used eighteen columns as my feature set: nine of them continuous, eight binary, and one ordinal. My final model was only marginally better than random guessing, but there was some interesting information in the coefficients. For example, I learned that homebuilt craft were much more likely to be involved in accidents not caused by human error, which makes sense. And mid-air accidents and instructional flights were much more likely to be caused by human error.
extremely online
I wanted to have fun with my model, even if its predictions were none too effective. So I used Flask and some rudimentary HTML and CSS to create a little web app, where the user is presented with all of the features from a random real aircraft in the dataset, and has to decide for themselves what was the cause of the crash. Your guess is then compared to that of the logistic regression model (this time trained on the entire data), which I (a marketing genius) rebranded as Crashify.ai™. Finally, you can click a link to see the actual NTSB report for the accident in question. It’s fun! And macabre! You can play it here:
Please note that it’s running on a free-tier Heroku dyno, so it might take a few seconds to start up. And if the results screen gives you an error, just refresh it, that sometimes happens the first time.
so what
What did I learn from all this?
- Most plane accidents involve very small, non-commercial craft, and most of them are not fatal
- Relational databases are a great way to store complex and multi-tiered data, even if getting that data out can be a little tricky
- Even high-quality, government-produced data needs to be cleaned
- Machine learning isn’t magic, and you can’t necessarily predict something that’s just inherently difficult to determine, even with plenty of data
- A simple web app is a great way to turn something as abstract as a logistic regression model into a concrete toy, and Flask is a fantastic tool for that
Safe travels!
-
They also investigate major road, sea, and pipelines accidents. Neat! ↩
-
One example of a three-craft accident was this one in Boulder, Colorado in 2010, in which two small planes didn’t see each other in overcast weather, collided in mid-air, and one of them happened to be towing a glider (craft #3). ↩