project four - nobody knows you're a bot
Every week, the New Yorker magazine runs a caption contest. I’ve entered this contest, unsuccessfully, dozens of times. The problem is that I’m not very funny. But computers? Computers are funny as hell. What if I could have one write captions for me?
So: the contest. There’s a single-panel cartoon, nearly always of a character saying something to another character. The situation is wacky, perhaps even zany. You write what you think the speaking character is saying, and two weeks later the magazine prints the three funniest captions.

How do they pick the three finalists? Originally, an intern just read through the submissions every week, pulled out the ones that made them laugh, and sent those along to the cartoon editor, who chose his top three from that list. But as the magazine (and wannabe gagsters) got increasingly online, the number of weekly submissions grew into the thousands, and this low-tech method became unwieldy.
Starting in 2015, the magazine decided to crowdsource the intern’s job of sifting through the submissions for the handful of gems. They used a system called NEXT, developed by some friendly-looking engineers from Wisconsin, who were nice enough to put all their data in a public Github repository, just for me.
By the way, you can do some ratings yourself right now. Reading increasingly worse jokes for the same cartoon over and over: it’s remarkably depressing!

Instead of messing around with the Data.World stuff, I just cloned the whole repo and started poking around. There’s a lot in there, but the data I was interested in (the actual caption submissions) was located in contests/summaries/, in a set of CSV files, one for each week’s contest.
The CSV file names had some interesting clues in them. From contest number 510 through 560, each one has a _LilUCB.csv or _RoundRobin.csv suffix (sometimes one of each), but from #561 onward they all end with _KLUCB.csv. These turned out to refer to the algorithms used to choose which captions to display to joke-raters. LilUCB and KLUCB are Upper Confidence Bound solutions to the multi-armed bandit problem. Essentially, the developers at NEXT want highly-rated captions to be shown to more people, so that volunteer gag-raters don’t get worn down by all the really bad puns and Trump jokes. They experimented with a few solutions, and after contest 561 they apparently settled on KLUCB as their favorite algorithm.
When I started working on this project, the most recent contest was #661. If I only used the KLUCB data, this gave me just around 100 contests to work with - about 600,000 captions.
Working with a hundred CSV files is a little inconvenient, so I wrote a function that reads these files into a local MongoDB database, with each caption existing as a ‘document’ in the database. This made it easy to extract data as needed, or (for example) quickly search all 600,000 captions for the phrase “I’d like to add you to my professional network on LinkedIn”. (It appears, in some form, twelve times.)1
MongoDB is great for this kind of storage and retrieval, but I didn’t just want to read captions. I wanted to write them!
text text text
I thought about training a neural network text generator on all 600,000 captions. But this seemed unnecessarily cruel, and more importantly, I wanted the generated captions to relate to the actual cartoon as much as possible. On the other hand, I didn’t want to train a separate generator on each cartoon in my dataset, because I wanted to be able to generate viable captions for upcoming contests, not past ones.
It seemed like New Yorker cartoons tended to revisit the same themes again and again. What if I grouped my 100 cartoons into a smaller number of recurring categories, and use those as the basis for training my text generators? Then I could look at each week’s new contest, say “oh, this one is about doctors,” fire up my Doctors caption generator, and I’m off the the races.
How to categorize these cartoons? Well, I had all these thousands of captions for each one - what if I could use all this text to discover which cartoons were similar to each other, without knowing ahead of time exactly what my categories were going to be? That is, let my data run around the playground unsupervised?
Before I could use all this text, though, I need to turn it into numbers. Computers can’t read, but they love numbers.
There are a lot of ways to turn text into numbers (i.e., vectorization). Two of the most common are count vectorization and tf-idf vectorization. Both of these do basically the same thing: using each word2 as a separate column in an enormous table, count how many times that word appears in each document. Count vectorization uses the raw counts, while tf-idf normalizes these counts using the overall rarity of each word.
I wanted to focus on interesting words, not boring stuff like “I” and “the” and “with.” These uninteresting words are called “stop words,” and while the scikit-learn library has a built-in list of these, they explicitly tell you not to use it in their documentation. So I created my own list of stop words using the max_df parameter in CountVectorizer,3 which generates a list of tokens that appear in more than a given percentage of documents. After some trial and error, I used a cutoff of 1% to generate my stop-word list, and then manually removed two “interesting” words from that which I wanted to keep (“dog” and “work”).
But hang on. So far I’m working with captions as my unit of interest, but I’m actually interested in categorizing entire cartoons. So, for each cartoon, I combined all of the captions into a single giant blob of text, and vectorized them using tf-idf and the previously derived stop word list.
topic modeling
Now that all my text has been turned into tidy little numbers, I can use various dimensionality reduction techniques to try to find underlying similarities between cartoons. What words tend to appear together in our caption texts?
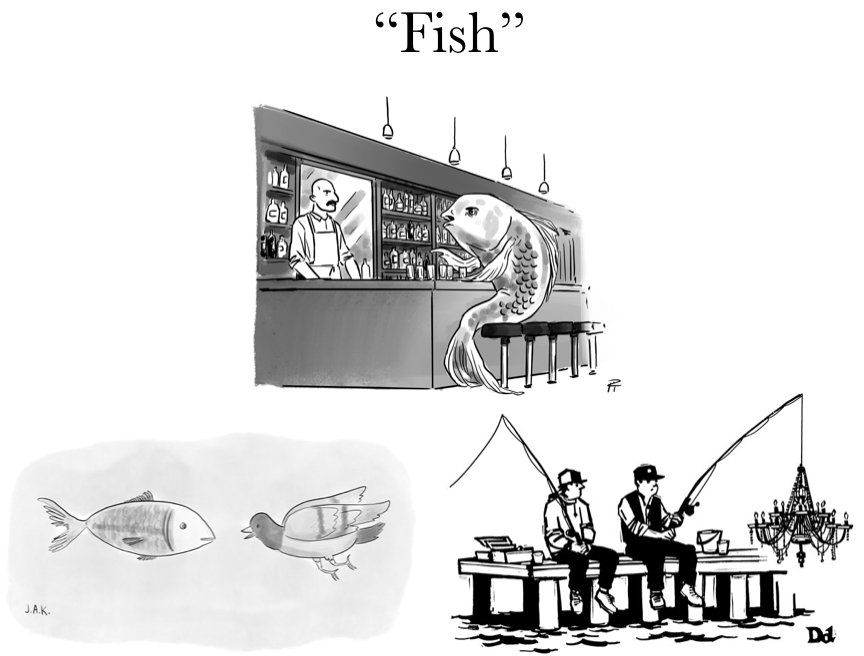
I tried several dimensionality reduction tools (such as truncated SVD, latent Dirichlet allocation), but non-negative matrix factorization seemed to give the best results. “Best” is somewhat subjective here, since I couldn’t rely on traditional metrics like accuracy or mean squared error to figure out how “good” my topic lists were. (Clustering metrics do exist, but many of them rely on having a set of correctly labeled cases, or at least knowing what or how many topics you’re even looking for.) In the end, I settled on 20 topics. Fewer than that and some of my sample word lists seemed to combine multiple different concepts; more than that, and they started to seem to apply to single cartoons only. Here are six of those twenty topics, with the top ten most representative words in that topic. (Nothing in the data labeled these topics as “fish” or “knights” or whatever - that’s just my opinion of what each topic seemed to be about.)

But I didn’t just want a list of topics - I wanted to classify my hundred cartoons into distinct groups, so I could use their caption submissions as text-generation fuel. One quick way to do this would be to simply assign each cartoon the category associated with the highest-value feature, but this ends up throwing nearly all of the cartoons into a single category, which is not ideal. What I really wanted was to cluster my cartoons into separate groups. Luckily, there are some algorithms for that!
clustering
The scikit-learn library comes with at least ten clustering models, and I tried most of them. Some, like DBSCAN and OPTICS, automatically4 find how many clusters exist in the data, assigning everything else to a ‘noise’ category; others take in a number of expected clusters and do their best to assign everything to one, usually (in my case) dumping the majority into a single large category functionally similar to the DBSCAN/OPTICS ‘noise’ cluster.
These clustering algorithms didn’t perform very well on the 20 topics generated by NMF above; in the end, I ran them on the large feature matrix generated by tf-idf. I ‘scored’ them using a function I wrote to display the actual cartoons associated with each contest - for example, if a cluster of three cartoons all involved fish or fishing, I assigned it the ‘fish’ label.
In the process of doing this, I noticed that a few of the contests had the wrong cartoon illustration in the contests/info/adaptive/ directory, and three of them (contest numbers 644, 647, and 656) were complete duplicates of the previous week’s data. I re-imported my data from MongoDB after fixing this, and left an as-yet-unanswered comment on the repo page.
In the end, none of the clustering algorithms yielded perfect results. All of them generated at least a few clusters that included more than one basic type of cartoon, like “birds / crime” or “death / party.” I wound up using the clusters generated by three different algorithms - DBSCAN, hierarchical agglomerative clustering, and spectral clustering - throwing them into a CSV file and manually assigning a consensus label based on the most commonly assigned topics and my own subjective feelings.
I ended up with eighteen cartoon categories, from Art to Work, with a final Other category including everything that didn’t fit into one of the others. I was surprised that some New Yorker clichés, like the desert island or therapist’s office, didn’t make it in there (although Doctors was one). And there were a lot more animal-themed cartoons than I expected. I don’t know what this means.
One last thing I had to do - for the larger categories, I wanted to be able to select only the top 1,000 or 1,500 captions from each contest to use in training, as ranked by the crowdsourced ratings. But there were four contests (#591, 592, 599, and 600) where something had gone terribly wrong and all of the captions were essentially tied. I got around this by assigning fake rankings to each caption based on their order of appearance in the file.
d e e p l e a r n i n g
Topic-labeled cartoons in hand, I was finally ready for the fun part: training neural networks to make jokes!
Specifically, character-based recurrent neural networks, which are a little bit like magic.5 I used Max Woolf’s implementation of a character-based RNN, which is helpfully pre-trained on enough Reddit junk that it doesn’t need to re-learn the basic rules of what English words and sentences look like every time.
Some experimentation on my own MacBook Air quickly made it clear why the documentation suggested using a powerful GPU to train. My underpowered laptop was taking several minutes for a single epoch of training; at that rate, it would have taken days or weeks to train twenty sets of weights to a reasonable level of fitness.
I could go on Amazon and buy a $6,500 video card, or I could just rent one for about 90 cents an hour. That would be the p2.xlarge EC2 instance on AWS (General Purpose GPU Extra Large), with a pre-installed Deep Learning AMI, which means I don’t have to mess around with getting Python and TensorFlow installed.
I scp’d my labeled captions to my fresh new instance and pip installed textgenrnn. It turned out that the hardest part about doing this on EC2 was making the remote Jupyter Notebook server accessible from my own browser. This walkthrough was extremely helpful in getting that set up.
It turns out the best thing about training a text-generation RNN is reading the early output, when it hasn’t really been properly trained yet. Here are some results from early on, training on all cat-related captions:
####################
Temperature: 0.2
####################
The cat is a cat to the cat to the cat.
He says that's all the cat on the cat food.
It's the one to tell him the cat for the court time the cat to the cat on the cat the cat.
####################
Temperature: 0.5
####################
He thinks I'm a good cat.
Don't really think it's time that well the cat something that there's a big pussycat.
We think he's the saddle part in the course at the first mouse throne.
####################
Temperature: 1.0
####################
It's tired of right! Then. You said "it is "too took is Ah'" time wearing a dog.
The cat one win in this cheese.
please lessue we’ve been everweretized to cute one under only gold of her
“Temperature” is a hyperparameter that adjusts the randomness of the predictions - essentially, low temperatures mean the RNN makes “safe” guesses about what the next character should be, while with high temperatures it starts getting crazy and taking all its clothes off. 0.5 gives us a nice balance, and is what I ended up using for the final app.
Once everything was up and running, training was a simple matter of training a weights file for each of my cartoon categories. The main trouble was that my connection to my remote instance sometimes timed out, and I’d lose whatever was currently going, so I learned to save my generated weights more frequently.
After some re-training of weights for a few categories that seemed a little undercooked, I had everything ready to go, and just needed to put together a nice interface so other people could play with it.
winning my webby award
Here’s the site. It’s pretty neat. One thing to note is that the cartoon that comes up when you select a category is just an example of one of the several cartoons used to train weights for that category; all of the categories include at least two cartoons, and the largest one (Other) has 25.

It’s written in Flask, with AJAXy stuff done in jQuery.6 Yes, it really is generating new captions on the fly - there are no pre-generated or cherry-picked lists. The hardest thing was figuring out how to reset the textgenrnn object when switching to a new category. The solution turned out to be importing the Keras backend and running its clear_session() method when a new category was selected.
so did you win the contest
Not yet.
-
I also discovered that someone has been submitting the caption “It’s a living!” every week for the past 33 weeks. God bless you, stranger. ↩
-
Token, actually, but words and tokens are roughly the same thing for my purposes here. ↩
-
Count Vectorization is the name of a cybernetic vampire and I will not be taking questions. ↩
-
Given correctly specified parameters, which in my experience can be extremely finicky. ↩
-
RNNs are actually considered old & busted now, and the new trend is attention-based networks like GPT-2. Max Woolf has written an interface for that as well, which is extremely fun to play with. ↩
-
I didn’t know a thing about JavaScript before this, so my “programming” “workflow” was basically copying stuff off StackOverflow and punching it in its stupid face until it worked. ↩